Machine Learning Lifecycle Process

Building and operating a typical ML workload is an iterative process, and consists of multiple phases. We identify these phases loosely based on the open standard process model for Cross Industry Standard Process Data Mining (CRISP-DM) as a general guideline.
CRISP-DM is used as a baseline because it’s a proven tool in the industry and is application neutral, which makes it an easy-to-apply methodology that is applicable to a wide variety of ML pipelines and workloads.
The end-to-end ML process includes the following phases:
- Business goal identification
- ML problem framing
- Data collection
- Data integration and preparation
- Feature engineering
- Model training
- Model validation
- Business evaluation
- Production deployment (model deployment and model inference)
This article presents a high-level overview of the various phases of an end-to-end ML lifecycle, which helps frame our discussion around security, compliance, and operationalization of ML best practices which will be useful in our later blog posts.
The machine learning lifecycle process
- The preceding figure describes the ML lifecycle process, along with the subject matter experts and business stakeholders involved through different stages of the process. It is also important to note that ML lifecycle is an interactive process.
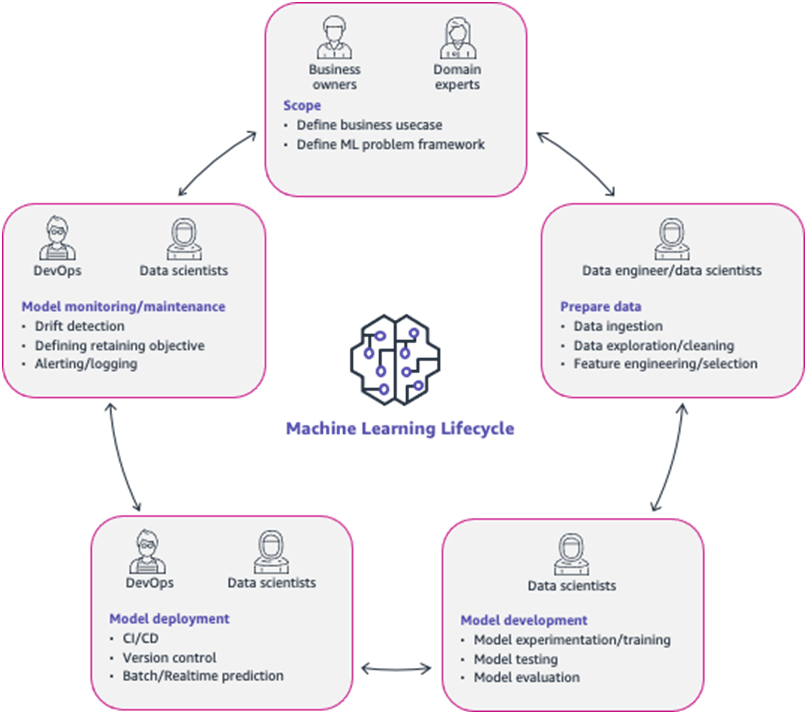 The machine learning lifecycle process
The machine learning lifecycle process
Phase 1
- Phase 1 is to define business problem and goals. Domain experts and business owners are most involved in this part, determining success metrics. KPIs and determining compliance and regulatory requirements also fall under this phase. Data scientists typically work with the SMEs to frame the business problem in a way that allows them to develop a viable ML solution.
Phase 2
Phase 2 involves gathering and preparing all relevant data from various data sources. This role is often performed by data engineers with expertise in big data tools for data extraction, transformation and loading (ETL). It is important to ensure that the data is versioned and the lineage of the data tracked for auditing and compliance purpose.
Once the raw datasets are available, data scientists perform data exploration, determine input features and target variables, outlier analysis, and necessary data transformations that may be needed. It is also important to ensure any transformations applied to training data can also be applied in production at inference time.
Phase 3
- Next is the model development and model evaluation phase. Data scientists determine the framework they want to use, define out-of-sample, out-of-time datasets, and experiment with various ML algorithms, hyperparameters, in some cases, add additional training data.
Phase 4
Next, you take the trained models and run them on out of time and out of sample datasets, and pick the model or models that return the best results close to the metrics determined in Phase 1. Model artifacts and any corresponding code must be properly versioned and stored in a centralized code repository or in an artifact management system.
Note that this stage of the process is experimental, and data scientists may go back to the data collection or feature engineering stage if the model performance is consistently poor. More details on data and ML artifact lineage are available in the Traceability section of this document.
Data scientists are also required to provide reasons or explain feature/model influence on predictions. Model interpretability is discussed in later sections.
Phase 5
The next phase is to deploy the models into production. This is often the most impactful and difficult step because of the gap between technologies and skillsets used to build and deploy models in production.
A large part of making this successful requires intense collaboration among infrastructure professionals such as DevOps engineers, data scientists, data engineers, domain experts, end users, and business owners during the decision making process. There should be standardized metrics, and all decision makers should be able to interpret them directly.
In most organizations, lifecycles of ML models end with the deployment phase. There is a need for some form of shadow validation where models are deployed but not integrated in the production workflow to capture differences between training and live data.
This ensures that the model continues to perform as expected when receiving data from production systems. Once this validation proves successful, the model's predictions can be used in production workflows.
However, for ML models to be effective in the long run, continuously monitoring the model in real-time (if possible) to determine how well it is performing is necessary, as the accuracy of models can degrade over time.
If the performance of a model degrades below a certain threshold, you may need to retrain and redeploy your model.
Hope this guide gives you an high level overview of Different phrases of Machine Learning Lifecycle.
Let me know your thoughts in the comment section 👇 And if you haven't yet, make sure to follow me on below handles:
👋 connect with me on LinkedIn 🤓 connect with me on Twitter 🐱💻 follow me on github ✍️ Do Checkout my blogs
Like, share and follow me 🚀 for more content.
{% user aditmodi %}
👨💻 Join our Cloud Tech Slack Community 👋 Follow us on Linkedin / Twitter for latest news 💻 Take a Look at our Github Repos to know more about our projects ✍️ Our Website




