Introducing Karpenter – An Open-Source High-Performance Kubernetes Cluster Autoscaler

At re:Invent 2021, AWS announced the v0.5.0 release of Karpenter, marking its open-source, Kubernetes node provisioning project as production ready. With Karpenter, Kubernetes users can now dynamically provision underlying compute nodes based on pod specifications more efficiently than the existing Kubernetes cluster-autoscaler project.
Karpenter is an open-source, flexible, high-performance Kubernetes cluster autoscaler built with AWS. It helps improve your application availability and cluster efficiency by rapidly launching right-sized compute resources in response to changing application load. Karpenter also provides just-in-time compute resources to meet your application’s needs and will soon automatically optimize a cluster’s compute resource footprint to reduce costs and improve performance.
Before Karpenter, Kubernetes users needed to dynamically adjust the compute capacity of their clusters to support applications using Amazon EC2 Auto Scaling groups and the Kubernetes Cluster Autoscaler. Nearly half of Kubernetes customers on AWS report that configuring cluster auto scaling using the Kubernetes Cluster Autoscaler is challenging and restrictive.
Kubernetes-native cluster autoscaler is now production-ready according to AWS.

So how does Karpenter work, and how is it different than cluster autoscaler?
Karpenter
- If you are familiar with GKE Autopilot’s dynamic node provisioning process, you can view Karpenter as an open-source version of that tool, designed to work with any Kubernetes cluster (NOTE: currently AWS is the only officially supported cloud provider).
Similar to GKE Autopilot, Karpenter observes the pod specifications of unschedulable pods, calculates the aggregate resource requests, and sends a request to the underlying compute service (e.g. Amazon EC2) with capacity needed to run all the pods.
Underneath the hood, Karpenter defines a Custom Resource called Provisioner to specify the node provisioning configuration including instance size/type, topology (e.g. zone), architecture (e.g. arm64, amd64), and lifecycle type (e.g. spot, on-demand, preemptible).
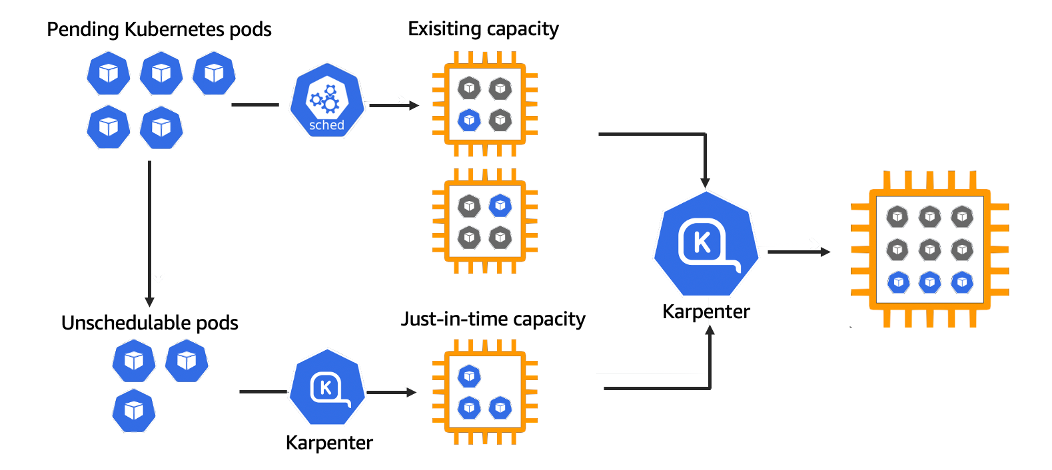
On the flip-side, Karpenter can also deprovision nodes when they are no longer needed. This can be determined by node expiry config (ttlSecondsUntilExpired) or when the last workload running on Karpenter provisioned node is terminated.
Either of these two events triggers a finalization, which cordons the nodes, drains the pods, terminates the underlying compute resource, and deletes the node object. This deprovisioning feature can also be used to keep the nodes up to date with the latest AMI as well.
Karpenter vs. Cluster Autoscaler
At a cursory look, Karpenter works similarly to the existing Kubernetes cluster autoscaler project. After all, cluster autoscaler is also cloud-agnostic and can scale up or down based on pod resource requests.
Upon a closer look, however, Karpenter provides several advantages over cluster autoscaler:
Kubernetes native scaling: Cluster autoscaler for AWS utilizes EC2 Auto Scaling groups to trigger scaling events. Since ASGs were designed before Kubernetes, this integration is clunky and slow. For example, managed node group users still can’t configure it to scale nodegroups to 0, making batch workload types more expensive to run on EKS.
No need to pre-provision node groups: Cluster autoscaler can only provision nodes based on specifications provided by node groups, which require worker groups to have specific tags and work best with similar instance types. This meant that if you wanted to run performance tests, you needed to predefine a node group with beefier EC2 machine types for cluster autoscaler to trigger scaling events. With Karpenter, you can utilize all of AWS instance types on demand. Since Karpenter manages each instance directly without node groups, it is also much faster to request a new compute instance when capacity is unavailable.
Faster scheduling: With cluster autoscaler, pods rely on kube-scheduler to create pods to new nodes once new resources become available. Since Karpenter manages nodes directly, it can immediately launch pods to new nodes without having to wait for the scheduler.
Conclusion
With Karpenter, we can offload node provisioning, autoscaling, and upgrades and focus on running our applications. Karpenter works with all kinds of Kubernetes applications, but it performs particularly well for use cases that require rapid provisioning and deprovisioning large numbers of diverse compute resources quickly. For example, this includes batch jobs to train machine learning models, run simulations, or perform complex financial calculations.
Let me know your thoughts in the comment section about the new karpenter service 👇 And if you haven't yet, make sure to follow me on below handles:
👋 connect with me on LinkedIn 🤓 connect with me on Twitter 🐱💻 follow me on github ✍️ Do Checkout my blogs
Like, share and follow me 🚀 for more content.
{% user aditmodi %}
👨💻 Join our Cloud Tech Slack Community 👋 Follow us on Linkedin / Twitter for latest news 💻 Take a Look at our Github Repos to know more about our projects ✍️ Our Website




