👋 Everything about EKS & AI Infrastructure Newsletter "#63" ☁️❤👨💻
Autonomous ops is no longer a stretch goal.

Dear EKS & AI Infrastructure enthusiasts,
Welcome to Everything about EKS & AI Infrastructure #62.
This week feels like a turning point edition.
AWS DevOps Agent hit GA with native EKS support. CloudWatch Container Insights went OTel. Global Accelerator landed natively in the Load Balancer Controller. And underneath all of it, a quieter but more important shift: the tooling for autonomous operations — self-healing infrastructure, agentic incident response, topology-aware root cause analysis — is no longer experimental. It’s production-grade and shipping fast.
We also have strong community contributions this week: migration toolkits, network cost dashboards, voice agents on EKS, and a PCI DSS compliance reference worth bookmarking if you’re in FSI.
And something a little different this week. Not about systems. About the people who made us.
Let’s get into it. 👇
- Performance Engineering in Modern AI Systems 🌩️
🌩️ Running Large-Scale GPU Workloads on Kubernetes with Slurm — NVIDIA Technical Blog
Most teams running large-scale AI training have years of investment in Slurm — job scripts, fair-share policies, accounting workflows. The problem is that Kubernetes has become the standard substrate for GPU infrastructure, and maintaining two separate scheduling environments is operationally expensive. Slinky, an open source project from SchedMD (now part of NVIDIA), solves this by representing all Slurm daemons as Kubernetes CRDs — slurmctld, slurmdbd, slurmd, slurmrestd — so a full Slurm cluster runs on Kubernetes infrastructure with complete lifecycle management.
NVIDIA runs this in production across clusters scaling to over 8,000 GPUs, with NCCL all-reduce and all-gather benchmarks showing no measurable performance difference from non-containerized Slurm. The operational wins compound at scale: Kubernetes node drains sync automatically to Slurm, PodDisruptionBudgets protect running jobs during rolling updates, and per-job GPU metrics are labeled with Slurm job IDs via DCGM Exporter — all without a separate HPC monitoring stack. The sharp constraint to know before adopting: slurm-operator assumes one worker pod per node, so the model pays off specifically for multinode job scheduling — single-node-only workloads are better served by slurm-bridge.

- Starred Content ⭐
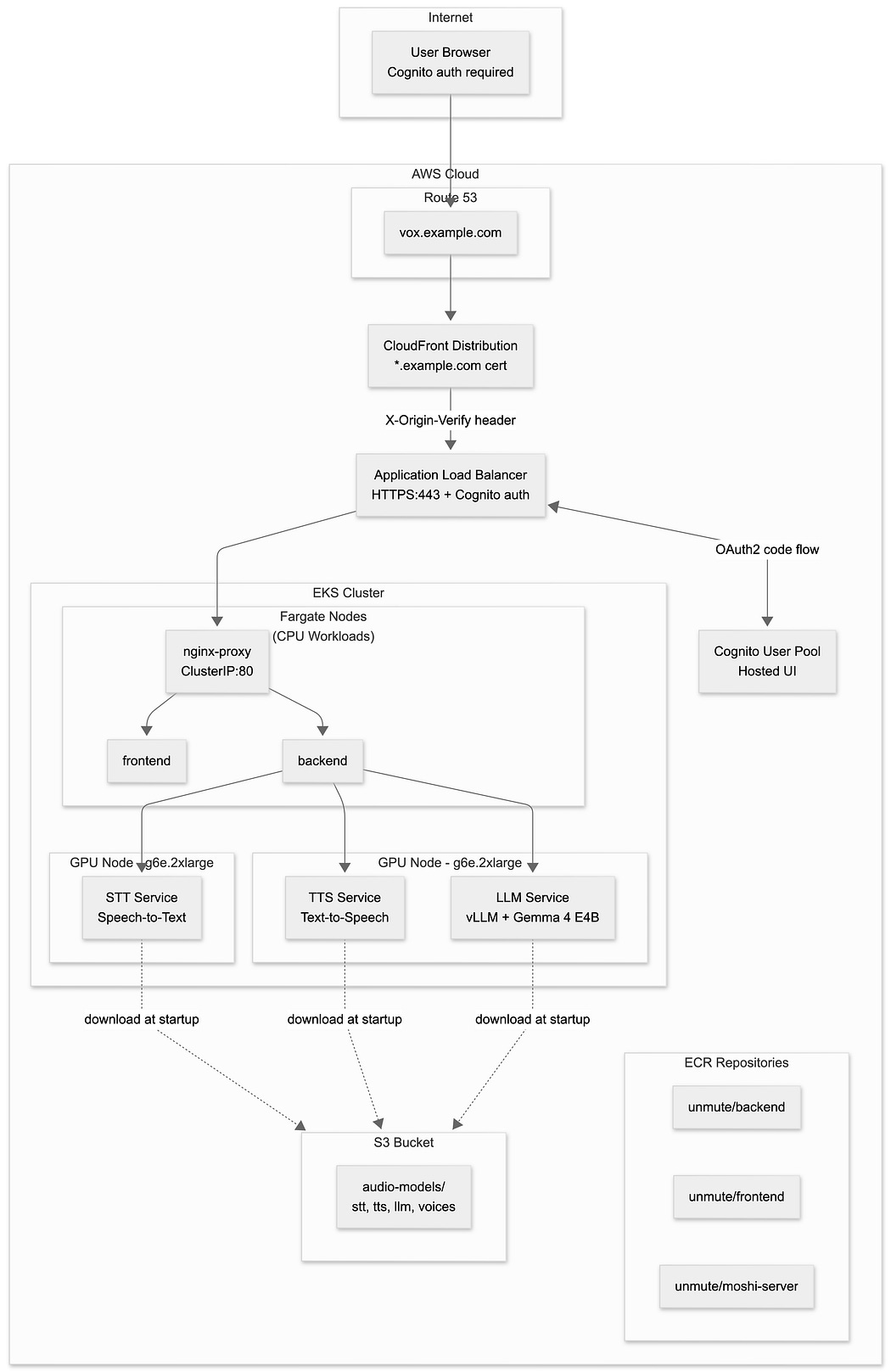
⭐ Sub-Second Voice Agents on Amazon EKS with Gemma 4 and Unmute (By Gary Stafford)
Real-time voice AI has a latency problem — STT, LLM inference, and TTS chained together almost always break the conversational feel. Gary Stafford’s writeup walks through how Kyutai Unmute’s streaming pipeline (STT → LLM → TTS in a single pass) gets end-to-end response times under a second, and why that threshold is what makes turn-taking feel natural rather than robotic.
The EKS architecture choices here are the sharp part — Gemma 4’s E2B–E4B variants run the multimodal reasoning on modest NVIDIA GPUs without blowing the latency budget, and Gary covers the observability decisions that keep this reliable under real load, not just demo conditions. If you’re thinking about voice agents on EKS, this is a concrete starting point, not a toy example.
⭐Building Intelligent Knowledge Graphs for Amazon EKS Operations Using AWS DevOps Agent
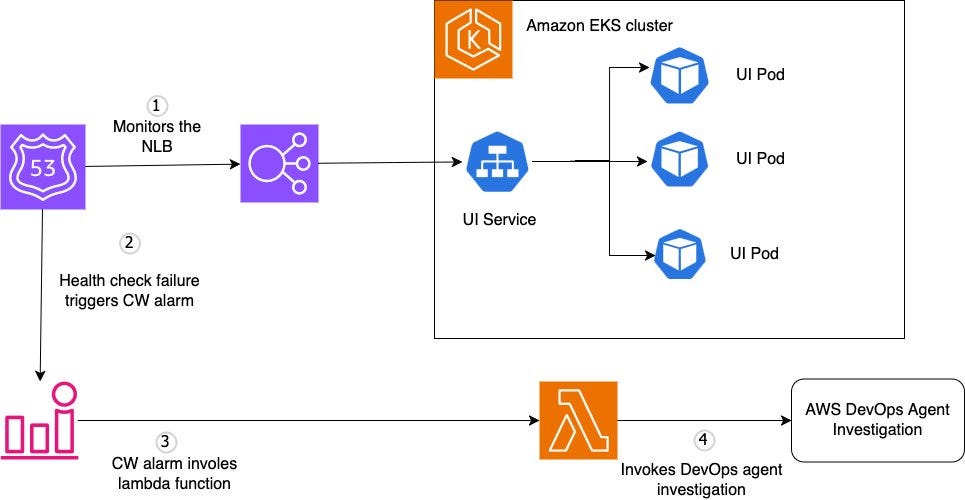
The observability problem on EKS isn’t data collection — it’s correlation. When something breaks, you have logs, metrics, traces, and pod events all in separate places, and the dependency chain between a failing pod, its upstream service, the load balancer, DNS, and cluster add-ons isn’t something any single tool surfaces automatically. AWS DevOps Agent approaches this differently by building a knowledge graph of the EKS environment proactively — mapping relationships across services, pods, networking, and add-ons before an incident starts, not after.
When a fault occurs, the agent traverses the graph to trace the dependency chain to the actual root cause rather than presenting raw telemetry for a human to correlate manually. The practical impact is on MTTI — the time between “something is broken” and “we know what caused it” — which is where most of the MTTR budget gets burned in production EKS environments. For teams already running structured observability tooling, this is worth understanding as a layer above your existing telemetry stack, not a replacement for it.
⭐Leverage Agentic AI for Autonomous Incident Response with AWS DevOps Agent
The incident response problem on distributed systems isn’t alerting — it’s correlation time. When a CloudWatch alarm fires at 2 AM, the signals for root cause are split across log groups, deployment timelines, DynamoDB metrics, and Lambda traces, and manually assembling that picture routinely takes hours. AWS DevOps Agent solves this by building a topology map of your environment, auto-discovering resources, their relationships, alarms, and log groups, so when a latency spike hits, it can trace the dependency chain from the symptom to the cause rather than presenting raw telemetry for a human to piece together. In the serverless URL shortener walkthrough in the post, the agent detects elevated 5xx errors, systematically tests hypotheses, identifies DynamoDB write throttling caused by a recent commit, and posts a complete root cause analysis with mitigation options to Slack in under 5 minutes from initial alarm.
The sharp architectural detail is the three-tier skill hierarchy. A background learning sub-agent continuously scans infrastructure, telemetry, and code to update the topology map, and analyzes past investigations to generate learned skills so after resolving the same class of incident multiple times, the agent skips exploratory hypotheses and goes straight to the relevant signals. Early production deployments are reporting up to 77% reduction in MTTR — WGU brought a Lambda-related service disruption from an estimated two hours down to 28 minutes. The EKS integration is native: the agent has direct introspection into Kubernetes clusters, pod logs, and cluster events, including for private clusters access that external LLM wrappers cannot replicate.
⭐Henrique Santana’s re:Invent 2025 Serverless & Containers Series — Complete
Henrique Santana, Principal Cloud Support Engineer at AWS and KubeCon speaker, spent the past few months working through every relevant breakout and lightning session from re:Invent 2025 and distilling each into a sub-10-minute read. The series covers Lambda Managed Instances, durable functions, EKS Auto Mode, ECS Managed Instances, agentic architectures on containers, and Kubernetes networking — the full surface area of what AWS shipped and presented on the containers and serverless front last November.
The format is the value here: each article extracts the key architecture decisions and resources from a session that originally ran an hour. If you missed re:Invent or watched a session once and want a faster way to revisit the substance, this is the reference to keep open. Credit to Henrique for doing the work to make the whole series available in one place.

⭐Building PCI DSS-Compliant Architectures on Amazon EKS — Piyush Mattoo, Mridul Chopra & Ted Tanner
A question that comes up constantly for teams processing payment card data on Kubernetes: does shared tenancy infrastructure meet PCI DSS requirements, or do you need Dedicated Hosts? The answer from this post — co-authored by a PCI DSS QSA — is that your node provisioning choice (Karpenter, Cluster Autoscaler, EKS Auto Mode, or manual) does not change the compliance requirements. What matters is the security controls implemented at the workload and cluster level: namespace isolation, Pod Security Standards, network policies, IAM, and monitoring.
The sharp detail worth pulling out: EBS volume encryption with KMS alone does not satisfy PCI DSS Requirement 3.5.1.2 for PAN protection — you need the AWS Encryption SDK to encrypt PAN before writing to EBS volumes. That’s the kind of non-obvious gap that shows up in audits, not architecture reviews. The post also covers Application Network Policies on EKS Auto Mode, which extend standard network policies with DNS-based FQDN filtering at Layer 7 — particularly useful for payment gateway integrations where external services have dynamic IPs that make IP/CIDR-based policies brittle. Bookmark this one if you’re in FSI or advising customers who are.
- Announcements 📢
📢AWS DevOps Agent is Generally Available — with Native EKS Support
AWS DevOps Agent is now GA. The EKS integration is the headline for this newsletter’s readers — the agent understands cluster topology, pod logs, and cluster events natively, not through a generic API wrapper. For teams running AI workloads on EKS where infrastructure complexity keeps climbing, the pitch is autonomous incident response as a baseline operational pattern rather than a stretch goal.
The performance trajectory is worth noting: when David Yanacek first demoed the agent in a New York Times interview earlier this year, it took 11 minutes to root cause a production issue. Running the same scenario last week, it completed in 4 minutes. That delta — same workload, faster resolution — is the compounding effect of the continuous learning layer that analyzes past investigations and gets sharper over time. If you read the DevOps Agent deep dive earlier in this issue, this is the GA signal to start evaluating it seriously.
Community & Career 🤝
🤝Modernizing VMware Applications with Agentic AI — AWS Webinar This Week
VMware licensing pressure has pushed a lot of enterprises into reactive migration mode — moving VMs without actually rethinking the application. This AWS webinar takes a different approach: walk through assessment, pick the right modernization path per app, and then actually modernize a Java application using Kiro — covering framework upgrades, containerization, and deployment to ECS or EKS.
AWS Transform handles the heavy lifting on discovery and planning — automating dependency mapping and network conversion at up to 80× the speed of manual methods. Kiro picks up from there as the agentic IDE for the actual code transformation — spec-driven development, automatic compilation error detection and fixes, and deployment-ready infra generated alongside the application code. If your team is still figuring out what the end-to-end modernization toolchain looks like in practice, register before it fills up.
🤝Self-Healing Infrastructure with OpenClaw and Terraform (By Hector Flores)
The 3 AM page problem has a straightforward framing: you need either a human who’s awake or a system that can fix itself. Hector Flores’s setup uses OpenClaw inside an OpenShell sandbox, with automated PR workflows that tear down and recreate environments on every push — and a notification layer where a DevBot sends deployment status over SMS, accepts debug instructions by reply, and can leave PR feedback that a local agent picks up to iterate on.
The architecture worth noting is the nesting: agents inside sandboxes, inside other sandboxes, each with defined input/output boundaries. The self-healing loop isn’t a single agent watching for failures — it’s a chain of agents collaborating across environment boundaries, where the output of one (PR feedback) becomes the input of the next (local iteration). The InfraHouse Terraform module packages the AWS side of this for teams who want to start from something concrete rather than build the scaffolding from scratch.
🤝Self-Managed Kubernetes to EKS Migration Toolkit — AWS Samples (By Pradip Kumar Pandey)
Migrating a self-managed Kubernetes cluster to EKS at enterprise scale isn’t a kubectl apply problem — it’s a data extraction, transformation, and phased deployment problem with a lot of ways to break prod quietly. Pradip Kumar Pandey’s toolkit on AWS Samples approaches this with automated extraction of existing cluster configuration, transformation into EKS-compatible state, and phased deployment with built-in validation gates at each step rather than a single big-bang cutover.
The value of publishing this as a reusable toolkit rather than a blog walkthrough is that the edge cases are already encoded — the validation logic, the transformation rules, the rollback points. If your team is sitting on a self-managed cluster and the EKS migration conversation keeps getting deferred because the scoping feels unbounded, this is a practical starting point worth reviewing before your next planning cycle.
🤝Network Cost Dashboard for EKS (By Jeremy Cowan)
Network costs on EKS are notoriously hard to attribute — traffic flows through multiple hops, pods come and go, and the bill arrives as a lump sum with no pod-level breakdown. Jeremy Cowan’s network cost dashboard uses enhanced network observability data from EKS to calculate costs per network flow and surface them at the pod level, making showback and chargeback models actually implementable rather than theoretical.
For platform teams that own shared EKS infrastructure and need to allocate costs back to product teams, this closes a real gap — most cost allocation tooling handles compute and storage reasonably well but treats network as an afterthought. Worth a look if network spend is showing up as an unexplained line item in your cloud bill.
- Highlights ✨
✨ AWS Global Accelerator Now Natively Supported in AWS Load Balancer Controller
Until now, wiring AWS Global Accelerator to an EKS workload meant stepping outside Kubernetes entirely — console, CLI, or CloudFormation — which created a separate management plane prone to configuration drift and no visibility into accelerator state from within the cluster. The new AWS Global Accelerator Controller, part of AWS Load Balancer Controller v2.17.0+, solves this with a single GlobalAccelerator CRD that manages the full hierarchy — accelerators, listeners, endpoint groups, and endpoints — declaratively alongside your other Kubernetes resources.
The controller supports automatic endpoint discovery from existing Ingress, Service, and Gateway API resources, handles full lifecycle management including status reporting back into the CRD, and supports multi-region failover, weighted blue-green deployments, client affinity via SOURCE_IP, port overrides, and BYOIP. Two limitations worth knowing before adopting: BYOIP addresses cannot be changed after accelerator creation without recreating it, and auto-discovery only works within the same region as the controller — cross-region endpoints require manual ARN configuration.
✨ CloudWatch OTel Container Insights for EKS — Public Preview
CloudWatch Container Insights now collects metrics via OTLP from open source and AWS collectors, with each metric automatically enriched with up to 150 labels — Kubernetes metadata plus any custom labels like team, application, or business unit. The CloudWatch Observability EKS add-on handles installation and auto-detects accelerated hardware including NVIDIA GPUs, EFA, Trainium, and Inferentia — and for existing add-on users, OTel and legacy Container Insights metrics can run in parallel. PromQL via CloudWatch Query Studio is the headline for teams already invested in the Prometheus ecosystem. Free during preview; available in us-east-1, us-west-2, ap-southeast-1, ap-southeast-2, and eu-west-1.
✨AppRunner Heading to EOL — Lambda May Be the Real Replacement
AppRunner made container deployments genuinely simple — bundled load balancer, one-click TLS, and a provisioned vs. active pricing model that kept costs low for low-traffic apps. With it heading toward EOL, the obvious migration path is ECS, but that brings back exactly the complexity AppRunner was designed to hide. Lambda’s recent managed instances launch and long-standing container image support suggest a different landing spot — one that preserves the simplicity without the operational overhead. Worth watching how fast Lambda closes the remaining gaps.
🎉 Sponsor Section
At the moment, we don’t have a sponsor for this edition, but we look forward to working with companies and organizations that support the EKS & AI Infrastructure community in future editions. If you or your company is interested in sponsoring, please contact us at 📧 thecloudtechforall@gmail.com
📝 Words from the Author
The People Who Believed Before You Did
Somewhere along the way, someone looked at you — before the certifications, before the job title, before you had anything to show — and said you can do this. Not because the evidence was overwhelming. But because they saw something in you that you hadn’t learned to see in yourself yet.
For me, that moment came earlier than I could fully appreciate at the time. A teacher who didn’t just teach a subject but made me feel like I belonged in the room. A parent who never questioned whether the path I was choosing made sense, even when it wasn’t clear to anyone including me. A manager early in my career who gave me a problem that was too big for me — and then stood behind me anyway while I figured it out.
We spend a lot of time in this newsletter talking about systems — how they scale, how they fail, how they heal. But the most important infrastructure in anyone’s career isn’t the tech stack. It’s the people who held the load while you were still finding your footing.
If you have someone like that in your life — reach out this week. Not with a long message. Just enough to say: I still think about what you did for me.
And if you’re in a position now where someone younger is looking to you for that signal — give it generously. It costs you almost nothing. To them, it might be everything.
Happy Building! 😎




