Best practices for ML lifecycle stages

Building a machine learning model is an iterative process. For a successful deployment, most of the steps are repeated several times to achieve optimal results. The model must be maintained after deployment and adapted to changing environment. Let’s look at the details of the lifecycle of a machine learning model.
Data collection
The first step in the development of ML workloads is identification of data that is needed for training and performance evaluation of an ML model.
In the cloud environment, a data lake usually serves as a centralized repository that enables you to store all structured and unstructured data regardless of scale.
AWS provides a number of ways to ingest data, both in bulk and in real-time, from a wide variety of sources. You can use services such as AWS Direct Connect and AWS Storage Gateway to move data from on-premises environments, and tools like AWS Snowball and AWS Snowmobile for moving data at scale.
You can also use Amazon Kinesis to collect and ingest streaming data. You also have the option to use services such as AWS Lake Formation and Amazon HealthLake to quickly set up data lakes.
The following best practices are recommended for data collection and integration:
Detail and document various sources and steps needed to extract the data. This can be achieved using AWS Glue Catalog, which automatically discovers and profiles your data, and generates ETL code to transform your source data to target schemas. AWS also recently announced a new feature named AWS Glue DataBrew, which provides a visual data preparation interface that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and ML.
Define data governance — Who owns the data, who has access, the appropriate usage of the data, and the ability to access and delete specific pieces of data on demand. Data governance and access management can be handled using AWS Lake Formation and AWS Glue Catalog.
Data integration and preparation
An ML model is only as good as the data being used to train it. Bad data is often referred to as “Garbage in, Garbage out”. Once the data has been collected, the next step is to integrate, prepare and annotate data. AWS provides a number of services that data engineers and data scientists can use to prepare their data for ML model training.
In addition to the services such as AWS Glue and Amazon EMR, which provide traditional ETL capabilities, AWS also provides tools as part of Amazon SageMaker, designed specifically for data scientists. These include:
- Amazon SageMaker Ground Truth, which can be used for data labeling
- SageMaker Data Wrangler, which simplifies the process of data preparation and feature engineering
- SageMaker Feature Store, which enables you to store, update, retrieve, and share ML features
Additionally, SageMaker Processing allows you to run your pre-processing, post- processing, and model evaluation workloads on a fully managed environment.
We recommend implementation of the following best practices for data integration and preparation:
Track data lineage so that the location and data source is tracked and known during further processing. Using AWS Glue, you can visually map the lineage of their data to understand the various data sources and transformation steps that the data has been through. You can also use metadata provided by AWS Glue Catalog to establish data lineage. The SageMaker Data Wrangler Data Flow UI provides a visual map of the end-to-end data lineage.
Versioning data sources and processing workflows — Versioning data sources processing workflows enables you to maintain an audit trail of the changes being made to your data integration processes over time, and recreate previous versions of your data pipelines. AWS Glue provides versioning capabilities as part of AWS Glue Catalog, and AWS Glue Schema Registry (for streaming data sources). AWS Glue and Amazon EMR jobs can be versioned using a version control system such as AWS CodeCommit.
Automate data integration deployment pipelines — Minimize human touch points in deployment pipelines to ensure that the data integration workloads are consistently and repeatedly deployed, using a pipeline that defines how code is promoted from development to production. AWS Developer Tools allow you to build CI/CD pipelines to promote your code to a higher environment.
Feature engineering
Feature engineering involves the selection and transformation of data attributes or variables during the development of a predictive model. Amazon SageMaker Data Wrangler can be used for selection, extraction, and transformation of features.
You can export your data flow, designed in Data Wrangler, as a Data Wrangler Job, or export to SageMaker Pipelines.
ETL services like Amazon EMR and AWS Glue can be used for feature extraction and transformation. Finally, you can use Amazon SageMaker Feature Store to store, update, retrieve and share ML features.
The following best practices are recommended for feature engineering:
- Ensure feature standardization and consistency — It is common to see a different definition of similar features across a business. The use of Amazon SageMaker Feature Store allows for standardization of features, and helps to ensure consistency between model training and inference.
- If you are using SageMaker for feature engineering, you can use SageMaker Lineage Tracking to store and track information about the feature engineering steps (along with other ML workflow steps performed in SageMaker).
Model training
The model training step involves the selection of appropriate ML algorithms, and using the input features to train an ML model. Along with the training data (provided as input features prepared during the feature engineering stage), you generally provide model parameters to optimize the training process.
To measure how well a model is performing during training, AWS uses several metrics such as training error and prediction accuracy. Metrics reported by the algorithm depend on the business problem and the ML technique being used.
Certain model parameters, called hyperparameters, can be tuned to control the behavior of the model and the resulting model architecture. Model training typically involves an iterative process of training a model, evaluating its performance against relevant metrics, and tuning the hyperparameters in search for the most optimal model architecture.
This process is generally referred to as hyperparameter optimization. AWS recommends the application of the following best practices during the model training step:
- Follow a model testing plan and track your model experiments — Amazon SageMaker Experiments enables you to organize, track, compare, and evaluate ML experiments and model versions.
- Take advantage of managed services for model turning — SageMaker Automatic Model Tuning and SageMaker Autopilot help ML practitioners explore a large number of combinations to automatically and quickly zoom in on high- performance models.
- Monitor your training metrics to ensure your model training is achieving the desired results — SageMaker Debugger can be used for this purpose, which is designed to profile and debug your training jobs to improve the performance of ML models.
- Ensure traceability of model training as part of the ML lifecycle — SageMaker Lineage Tracking can be used for this purpose.
Model validation
After the model has been trained, evaluate it to determine if its performance and accuracy will enable you to achieve your business goals. Data scientists typically generate multiple models using different methods, and evaluate the effectiveness of each model.
The evaluation results inform the data scientists’ decision to fine-tune the data or algorithms to further improve the model performance.
During fine-tuning, data scientists might decide to repeat the data preparation, feature engineering, and model training steps. AWS recommends the following best practices for model validation:
- Keep track of the experiments performed to train models using different sets of features and algorithms — Amazon SageMaker Experiments, as discussed in the Model training section, can help keep track of different training iterations and evaluation results.
- Maintain different versions of the models and their associated metadata such as training and validation metrics in a model repository — SageMaker Model Registry enables you to catalog models for production, manage model versions, manage approval status of the models, and associate metadata, such as the training metrics of a model.
- Transparency about how a model arrives at their predictions is critical for regulators who require insights into how a model makes a decision — AWS recommends that you use model explainability tools, which can help explain how ML models make predictions. SageMaker Clarify provides the necessary tools for model explainability.
- Biases in the data can result in can introduce bias in ML algorithms, which can significantly limit the effectiveness of the models. This is of special significance in healthcare and life sciences, because poorly performing or biased ML models can have a significant negative impact in the real-world. SageMaker Clarify can be used to perform the post-training bias analysis against the ML models.
Additional considerations for AI/ML compliance
- Additional considerations include:
- Auditability
- Traceability
- Reproducibility
- Model monitoring
- Model interpretability
Auditability
Another consideration for a well governed and secure ML environment is having a robust and transparent audit trail that logs all access and changes to the data and models, such as a change in the model configuration, or the hyperparameters.
AWS CloudTrail is one service that will log, nearly continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail logs every AWS API call, and provides an event history of your AWS account activity, including actions taken through the AWS Management Console, AWS SDKs, command line tools, and other AWS services.
Another service, AWS Config, enables you to nearly continuously monitor and record configuration changes of your AWS resources. More broadly, in addition to the logging and audit capabilities, AWS recommends a defense in depth approach to security, applying security at every level of your application and environment.
AWS CloudTrail and AWS Config can be used as Detective controls responsible for identifying potential security threats or incidents.
As the Detective controls identify potential threats, you can set up a corrective control to respond to and mitigate the potential impact of security incidents.
Amazon CloudWatch is a monitoring service for AWS resources, which can trigger CloudWatch Events to automate security responses. For details on setting up Detective and corrective controls, refer to Logging and Monitoring in AWS Glue.
Traceability
Effective model governance requires a detailed understanding of the data and data transformations used in the modeling process, in addition to nearly continuous tracking of all model development iterations.
It is important to keep track of which dataset was used, what transformations were applied to the data, where the dataset was stored, and what type of model was built.
Additional variables, such as hyperparameters, model file location, and model training metadata also need to be tracked. Any post-processing steps that have been applied to remove biases from predictions during batch inference also need to be recorded.
Finally, if a model is promoted to production for inference, there needs to be a record of model files/weights used in production, and model performance in production needs to be monitored.
One aspect of traceability that helps ensure you have visibility of what components or artifacts make their way into production, and how they evolve over time in the form of updates and patches, is the use of versioning.
There are three key components that provide versioning for different types of components involved in developing an ML solution:
- Using software version controls through tools such as GitHub to keep track of changes made to processing, training, and inference script. AWS provides a native version control system in the form of AWS CodeCommit that can be used for this purpose. Alternatively, you can use your own GitHub implementations.
- Using a model versioning capability to keep track of different iterations of models being created as part of iterative training runs. SageMaker Model Registry, which natively integrated with the wider SageMaker features, can be used for this purpose.
- Using a container repository to keep track of different container versions, which are used in SageMaker for processing, training, and inference. SageMaker natively integrates with Amazon ECR, which maintains a version of every container update.
Reproducibility
Reproducibility in ML is the ability to produce identical model artifacts and results by saving enough information about every phase in the ML workflow, including the dataset, so that it can be reproduced at a later date or by different stakeholders, with the least possible randomness in the process.
For GxP compliance, customers may need to reproduce and validate every stage of the ML workflow to reduce the risk of errors, and ensure the correctness and robustness of the ML solution.
Unlike traditional software engineering, ML is experimental, highly iterative, and consists of multiple phases that make reproducibility challenging. It all starts with the data. It’s important to ensure that the dataset is reproducible at each phase in the ML workflow.
Variability in the dataset could arise due to randomness in subsampling methods, creating train/validation/test splits and dataset shuffling.
Variability could also arise due to changes in the data processing, feature engineering, and post-processing scripts. Inconsistencies in any of these phases can lead to an irreproducible solution.
Methods that can help ensure reproducibility of the dataset as well as the data processing scripts include:
- Dataset versioning
- Using a fixed seed value across all the libraries in the code base
- Unit testing code to ensure that the outputs remain the same for a given set of inputs
- Version controlling the code base
The core components of the ML workflow are the ML models, which consist of a combination of model parameters and hyperparameters, which need to be tracked to ensure consistent and reproducible results.
In addition to these parameters, the stochastic (uncertain or random) nature of many ML algorithms adds a layer of complexity, because the same dataset along with the same code base could produce to different outputs.
This is more pronounced in deep learning algorithms, which make efficient approximations for complex computations. These results can be approximately reproduced with the same dataset, the same code base, and the same algorithm.
In addition to the algorithms, the underlying hardware and software environment configurations could impact reproducibility as well. Methods that can help ensure reproducibility and limit the number of sources of nondeterministic behavior in ML modeling include:
- Consistency in initializing model parameters
- Standardizing the infrastructure (CPUs and GPUs)
- Configuration management to ensure consistency in the runtimes, libraries and frameworks
When the solutions aren't fully deterministic, the need for quantifying the uncertainty in model prediction increases. Uncertainty quantification (UQ) plays a pivotal role in the reduction of uncertainties during optimization and decision making, and promotes transparency in the GxP compliance process.
A review of uncertainty quantification techniques, applications, and challenges in deep learning are presented in A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges.
Few methods for uncertainty quantification include:
Ensemble learning techniques such as Deep Ensembles, which are generalizable across ML models and can be integrated into existing ML workflows.
Temperature scaling, which is an effective post-processing technique to restore network calibration, such that the confidence of the predictions matches the true likelihood. Refer to a reference paper on calibrating neural networks.
- Bayesian neural networks with Monte Carlo dropout. For more information about these methods, refer to Methods for estimating uncertainty in deep learning.
Amazon SageMaker ML Lineage Tracking provides the ability to create and store information about each phase in the ML workflow. In the context of GxP compliance, this can help you establish model governance by tracking model lineage artifacts for auditing and compliance verification.
SageMaker ML Lineage Tracking tracks entities that are automatically created by SageMaker, or custom created by customers, to help maintain the representation of all elements in each phase of the ML workflow.
Model interpretability
Interpretability is the degree to which a human can understand the cause of a decision. The higher the interpretability of an ML model, the easier it is to comprehend the model’s predictions. Interpretability facilitates:
- Understanding
- Debugging and auditing ML model predictions
- Bias detection to ensure fair decision making
- Robustness checks to ensure that small changes in the input do not lead to large changes in the output
- Methods that provide recourse for those who have been adversely affected by model predictions
In the context of GxP compliance, model interpretability provides a mechanism to ensure the safety and effectiveness of ML solutions by increasing the transparency around model predictions, as well as the behavior of the underlying algorithm.
Promoting transparency is a key aspect of the patient-centered approach, and is especially important for AI/ML-based SaMD, which may learn and change over time.
There is a tradeoff between what the model has predicted (model performance) and why the model has made such a prediction (model interpretability).
For some solutions, a high model performance is sufficient; in others, the ability to interpret the decisions made by the model is key. The demand for interpretability increases when there is a large cost for incorrect predictions, especially in high-risk applications.
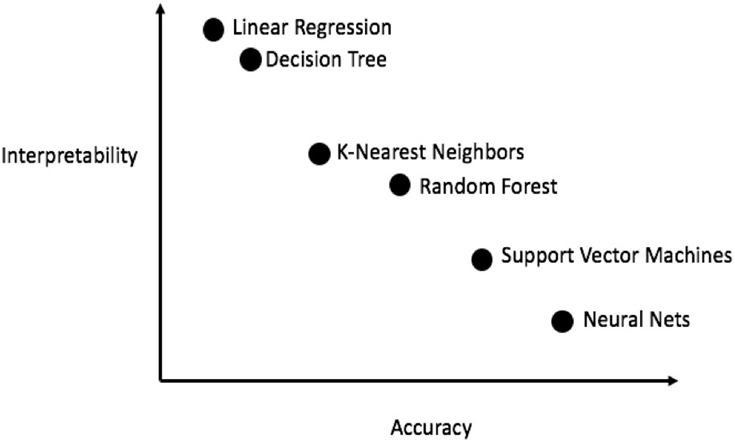 Trade-off between performance and model interpretability
Trade-off between performance and model interpretability
Based on the model complexity, methods for model interpretability can be classified into intrinsic analysis and post hoc analysis.
Intrinsic analysis can be applied to interpret models that have low complexity (simple relationships between the input variables and the predictions). These models are based on:
- Algorithms, such as linear regression, where the prediction is the weighted sum of the inputs
- Decision trees, where the prediction is based on a set of if-then rules
The simple relationship between the inputs and output results in high model interpretability, but often leads to lower model performance, because the algorithms are unable to capture complex non-linear interactions.
- Post hoc analysis can be applied to interpret simpler models, as described earlier, as well as more complex models, such as neural networks, which have the ability to capture non-linear interactions. These methods are often model- agnostic and provide mechanisms to interpret a trained model based on the inputs and output predictions. Post hoc analysis can be performed at a local level, or at a global level.
- Local methods enable you to zoom in on a single data point and observe the behavior of the model in that neighborhood. They are an essential component for debugging and auditing ML model predictions. Examples of local methods include:
- Local Interpretable Model-Agnostic Explanations (LIME), which provides a sparse, linear approximation of the model behavior around a data point
- SHapley Additive exPlanations (SHAP), a game theoretic approach based on Shapley values which computes the marginal contribution of each input variable towards the output
- Counterfactual explanations, which describe the smallest change in the input variables that causes a change in the model’s prediction
- Integrated gradients, which provide mechanisms to attribute the model’s prediction to specific input variables
- Saliency maps, which are a pixel attribution method to highlight relevant pixels in an image
- Local methods enable you to zoom in on a single data point and observe the behavior of the model in that neighborhood. They are an essential component for debugging and auditing ML model predictions. Examples of local methods include:
- Global methods enable you to zoom out and provide a holistic view that explains the overall behavior of the model. These methods are helpful for verifying that the model is robust and has the least possible bias to allow for fair decision making. Examples of global methods include:
- Aggregating local explanations, as defined previously, across multiple data points
- Permutation feature importance, which measures the importance of an input variable by computing the change in the model’s prediction due to permutations of the input variable
- Partial dependence plots, which plot the relationship and the marginal effect of an input variable on the model’s prediction
- Surrogate methods, which are simpler interpretable models that are trained to approximate the behavior of the original complex model
- Post hoc analysis can be applied to interpret simpler models, as described earlier, as well as more complex models, such as neural networks, which have the ability to capture non-linear interactions. These methods are often model- agnostic and provide mechanisms to interpret a trained model based on the inputs and output predictions. Post hoc analysis can be performed at a local level, or at a global level.
It is recommended to start the ML journey with a simple model that is both inherently interpretable and provides sufficient model performance.
In later iterations, if you need to improve the model performance, AWS recommends increasing the model complexity and leveraging post hoc analysis methods to interpret the results.
Selecting both a local method and a global method gives you the ability to interpret the behavior of the model for a single data point, as well as across all data points in the dataset.
It is also essential to validate the stability of model explanations, because methods in post-hoc analysis are susceptible to adversarial attacks, where small perturbations in the input could result in large changes in the output prediction and therefore in the model explanations as well.
Amazon SageMaker Clarify provides tools to detect bias in ML models and understand model predictions. SageMaker Clarify uses a model-agnostic feature attribution approach and provides a scalable and efficient implementation of SHAP.
To run a SageMaker Clarify processing job that creates explanations for ML model predictions, refer to Explainability and bias detection with Amazon SageMaker Clarify.
Model monitoring
After an ML model has been deployed to a production environment, it is important to monitor the model based on:
- Infrastructure — To ensure that the model has adequate compute resources to support inference workloads
- Performance — To ensure that the model predictions do not degrade over time
Monitoring model performance is more challenging, because the underlying patterns in the dataset are constantly evolving, which causes a static model to underperform over time.
In addition, obtaining ground truth labels for data in a production environment is expensive and time consuming. An alternative approach is to monitor the change in data and model entities with respect to a baseline.
Amazon SageMaker Model Monitor can help to nearly continuously monitor the quality of ML models in production, which may play a role in postmarket vigilance by manufacturers of Software as a Medical Device (SaMD).
SageMaker Model Monitor provides the ability to monitor drift in data quality, model quality, model bias, and feature attribution. A drift in data quality arises when the statistical distribution of data in production drifts away from the distribution of data during model training.
This primarily occurs when there is a bias in selecting the training dataset; for example, where the sample of data that the model is trained on has a different distribution than that during model inference, or in non-stationary environments when the data distribution varies over time.
A drift in model quality arises when there is a significant deviation between the predictions that the model makes and the actual ground truth labels.
SageMaker Model Monitor provides the ability to create a baseline to analyze the input entities, define metrics to track drift, and nearly continuously monitor both the data and model in production based on these metrics. Additionally, Model Monitor is integrated with SageMaker Clarify to identify bias in ML models.
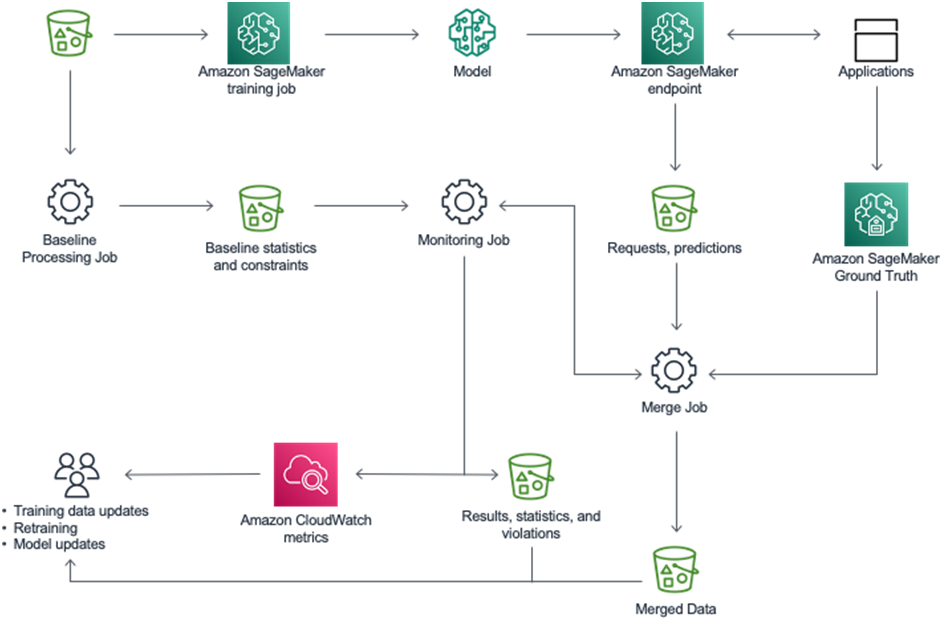 Model deployment and monitoring for drift
Model deployment and monitoring for drift
For model monitoring, perform the following steps:
After the model has been deployed to a SageMaker endpoint, enable the endpoint to capture data from incoming requests to a trained ML model and the resulting model predictions.
- Create a baseline from the dataset that was used to train the model. The baseline computes metrics and suggests constraints for these metrics. Real-time predictions from your model are compared to the constraints, and are reported as violations if they are outside the constrained values.
- Create a monitoring schedule specifying what data to collect, how often to collect it, how to analyze it, and which reports to produce.
Inspect the reports, which compare the latest data with the baseline, and watch for any violations reported and for metrics and notifications from Amazon CloudWatch.
The drift in data or model performance can occur due to a variety of reasons, and it is essential for the technical, product, and business stakeholders to diagnose the root cause that led to the drift.
*Early and proactive detection of drift enables you to take corrective actions such as model retraining, auditing upstream data preparation workflows, and resolving any data quality issues. If all else remains the same, then the decision to retrain the model is based on considerations such as:
- Reevaluate target performance metrics based on the use-case
- A tradeoff between the improvement in model performance vs. the time and cost to retrain the model
- The availability of ground truth labeled data to support the desired retraining frequency
- After the model is retrained, you can evaluate the candidate model performance based on a champion/challenger setup, or with A/B testing, prior to redeployment.
Hope this guide helps you understand the Best practices for ML lifecycle stages.
Let me know your thoughts in the comment section 👇 And if you haven't yet, make sure to follow me on below handles:
👋 connect with me on LinkedIn 🤓 connect with me on Twitter 🐱💻 follow me on github ✍️ Do Checkout my blogs
Like, share and follow me 🚀 for more content.
{% user aditmodi %}
👨💻 Join our Cloud Tech Slack Community 👋 Follow us on Linkedin / Twitter for latest news 💻 Take a Look at our Github Repos to know more about our projects ✍️ Our Website




