👋 Everything about EKS & AI Infrastructure Newsletter "#67" ☁️❤👨💻
DRA goes production-ready, six Kubernetes promotions land at once, and the Linux kernel under all of it has two unpatched CVEs with public exploits.

Dear EKS & AI Infrastructure enthusiasts,
Welcome to Everything about EKS & AI Infrastructure #67.
A lot happened this week, and most of it was consequential rather than just loud.
Kubernetes 1.36 shipped six DRA promotions in a single release — Prioritized List goes Stable, MIG workflows go declarative, hardware quarantine gets a real primitive. If you’ve been watching DRA from a distance waiting for it to be production-ready, this is the release where that waiting ends. The same release also brings Server-Side Sharded Watch to fix the controller scaling wall, Memory QoS to protect inference workloads under memory pressure, User Namespaces to GA, and in-place vertical scaling to Beta. It’s the most infrastructure-consequential Kubernetes release in a while.
On the AWS side, DRA now extends to both Trainium instances and EFA adapters — which means EKS finally has a coherent hardware-aware scheduling story across compute and networking together. NVIDIA open-sourced NVCF, bringing DGX Cloud-style multi-cluster GPU orchestration to anyone running their own infrastructure. And Shawn Zhang’s three-part series on running 100,000+ tenants on EKS is the architecture reference your team should read before committing to a design you’ll be refactoring at scale.
Underneath all of it: two unpatched Linux kernel CVEs with public proof-of-concept exploits. An attacker in any Pod on a vulnerable node reaches the kubelet API surface with host-root privileges. No distro-shipped patch yet for either. This one doesn’t wait.
Let’s get into it.👇
- Performance Engineering in Modern AI Systems 🌩️
🌩️Kubernetes 1.36: DRA Reaches Production-Grade Ergonomics
When you run AI workloads on Kubernetes, you need to tell the scheduler what hardware your Pod needs — a GPU, a specific type of GPU, or ideally a ranked preference. Until now, the way to do that was rigid: you pinned to one device class, and if that class was unavailable, the Pod just didn’t schedule. Dynamic Resource Allocation (DRA) has been the Kubernetes-native answer to this since 1.27, but it was missing the ergonomics teams actually needed before committing to it in production.
1.36 ships six DRA promotions at once. The headliner is Prioritized List going Stable — a Pod can now express a real fallback chain (H100 → A100 → T4) and the scheduler honors it, degrading gracefully when your preferred GPU class is under capacity pressure. Partitionable Devices reaching Beta unlocks Multi-Instance GPU (MIG) workflows declaratively: you can now slice one H100 into seven independently schedulable instances without building a custom controller for it. Device Taints Beta gives you a quarantine primitive — mark a flaky GPU tainted, drain workloads off it, repair the node, without cordoning the entire host. If your team has been watching DRA from a distance waiting for it to be production-ready, this is the release where that waiting ends.
🌩️Kubernetes v1.36: Server-Side Sharded List and Watch
In Kubernetes, controllers watch resources — Pods, Nodes, Events — by opening a long-lived connection to the API server and receiving every change as it happens. This works fine on small clusters, but at tens of thousands of nodes the model breaks down: every replica of a horizontally scaled controller gets the full event stream, deserializes all of it, and discards most of it. Adding more replicas doesn’t distribute the load — it multiplies it, because each replica is paying the same full-stream cost independently.
Server-Side Sharded List and Watch moves the partitioning to the API server itself. Instead of every controller replica watching everything, the API server divides the watch stream into shards and each replica only receives events for objects it actually owns. For EKS teams running Karpenter, custom node lifecycle controllers, or large operator deployments, this is the fix for the CPU and memory ceiling you hit as your node count scaled — without changing controller logic or tuning watch parameters manually.
🌩️Kubernetes v1.36: Tiered Memory Protection with Memory QoS
When memory pressure builds on a Kubernetes node, the OOM killer steps in — and it doesn’t have opinions about which container matters more. A sidecar collecting metrics can trigger an eviction that takes down your inference Pod, or a batch job can compete for memory against a latency-sensitive serving container on the same node. Until now, the only real lever was setting hard limits and hoping nothing exceeded them.
Memory QoS tiered protection lets you declare a ranked memory preference at the Pod level. Guaranteed Pods get hard memory reservations that the kernel protects before reclaiming from lower tiers. Burstable and BestEffort Pods get progressively less protection. For AI inference on EKS — where you’re often running a serving container alongside logging sidecars and health check processes — this means the model stays in memory under pressure and the disposable workloads absorb the eviction instead.
🌩️NetEase Games: LLM Cold Start From 42 Minutes to 30 Seconds on Kubernetes
Cold start time for LLM inference Pods on Kubernetes is one of those costs that’s easy to ignore until it’s not — until an autoscaling event adds a new Pod and your users wait nearly an hour for it to be ready. NetEase’s NPC inference workload was hitting exactly that: 42 minutes per Pod from start to serving, across image pull, model load, GPU warm-up, and framework initialization stacked on top of each other.
They got it to 30 seconds through three mechanisms applied together: pre-warmed model layers stored in shared storage so the model isn’t loading from scratch on every start, GPU-aware scheduling that ensures the Pod lands on a node where the GPU is already initialized, and a pull-on-demand pattern that avoids pulling the full container image when only the inference shim is needed. The result is an 84x reduction, in production, with enough public detail to replicate the approach. If cold-start latency is a line item in your EKS inference platform work, this is the blueprint to copy before you build your own version of the same thing.
🌩️TokenSpeed: A Speed-of-Light Inference Engine for Agentic Workloads — LightSeek Foundation
Most inference engines were benchmarked and tuned for short-context, high-throughput serving — the kind of traffic that looks like a web API. Agentic workloads are a different shape: contexts routinely exceed 50K tokens, conversations span dozens of turns, and the bottleneck moves from raw throughput to per-user latency at sustained concurrency. TokenSpeed is built from first principles for exactly this regime, with a C++ FSM scheduler that separates the control plane from the execution plane and enforces KV cache safety at compile time instead of at runtime.
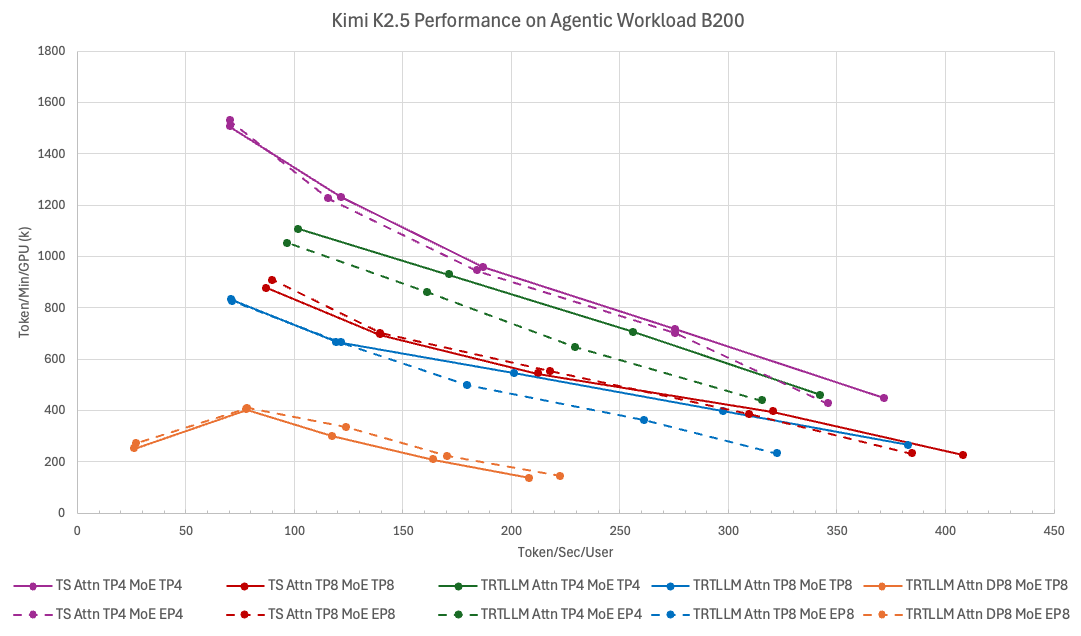
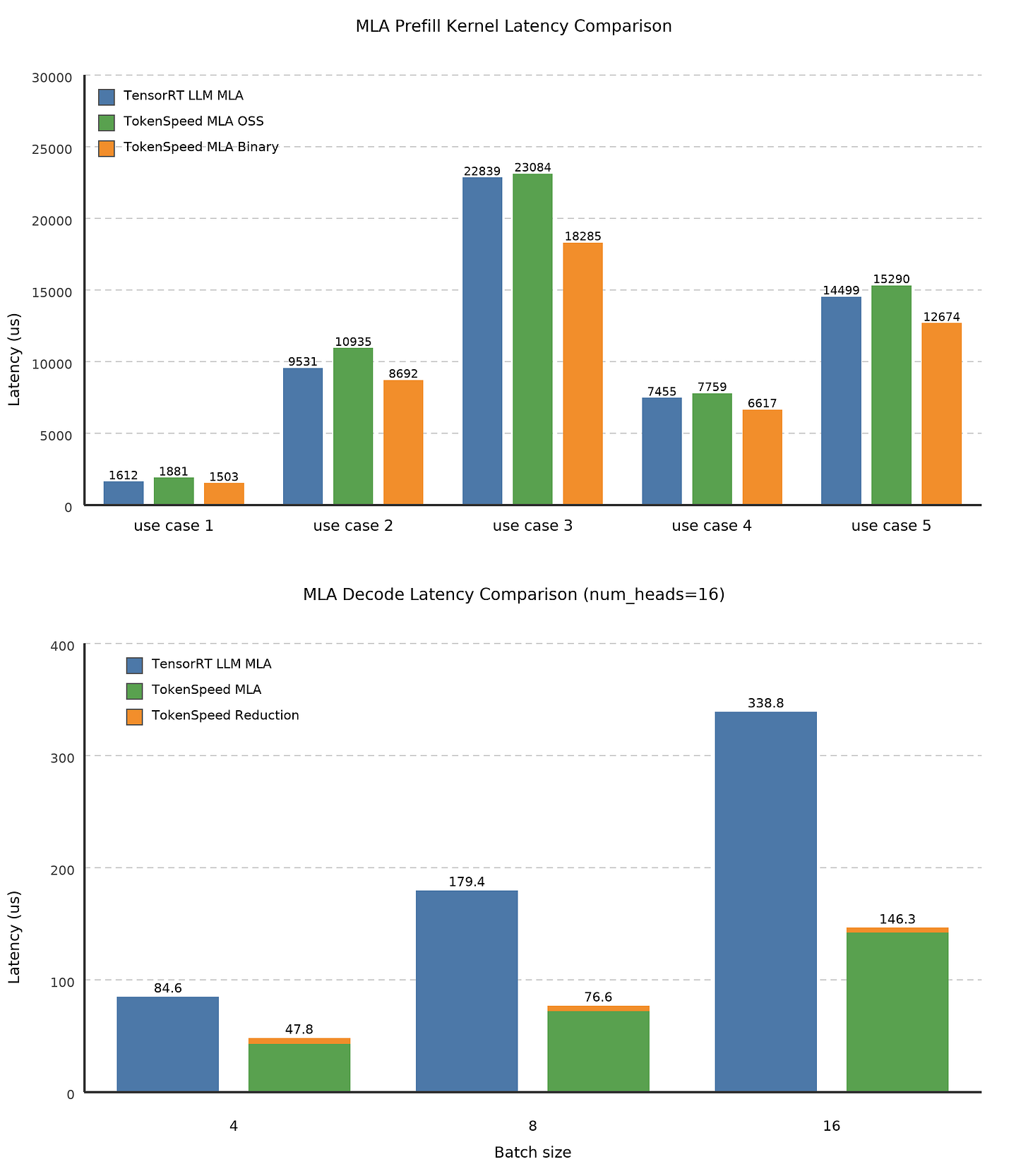
The benchmark target matters here — Kimi K2.5 and SWE-smith traces were used specifically because they mirror real coding-agent traffic, not synthetic prompts. Against TensorRT-LLM on that workload, TokenSpeed leads the Pareto frontier above 70 TPS/User, with roughly 9% faster min-latency at batch size 1 and 11% higher throughput around 100 TPS/User. The MLA kernel has already been adopted upstream into vLLM, which is the real signal: this isn’t a research project staying in its own repository. Co-developed across NVIDIA DevTech, AMD Triton, Qwen Inference, Together AI, Mooncake, and the NVIDIA Dynamo team — if you’re tuning inference serving on EKS, this engine and its kernel work is worth tracking closely.
Every Kubernetes node — including your EKS worker nodes — runs a Linux kernel shared across all the containers on that host. That shared kernel is what makes container workloads efficient, but it’s also why a kernel-level vulnerability is a cluster-wide problem, not just a node problem. Two new CVEs, collectively called Dirty Frag, chain together to give an unprivileged process root on the host from inside a container — no special setup, no prior access required.
Both flaws are in the Linux kernel’s networking layer (IPSec ESP and RxRPC modules), and both involve how the kernel handles in-memory page references during packet receive. CVE-2026-43284 has a fix in mainline Linux only — no distro-shipped kernel patch yet. CVE-2026-43500 has no patch merged anywhere. Public proof-of-concept exploits are already out. For EKS specifically: an attacker in any Pod on a vulnerable node reaches the kubelet API surface with node-root privileges. Mitigation while you wait: disable the affected kernel modules if your workload doesn’t use them, inventory your node AMI kernel versions today, and patch the moment your AMI ships the fix. If you run multi-tenant workloads — multiple teams’ Pods on shared nodes — this is the week to accelerate that.
- Starred Content ⭐
⭐CPU Inference and Orchestration on EKS — Guillermo Ruiz & Christian Melendez, AWS
Every conversation about AI infrastructure defaults to GPUs. The question of whether a workload actually needs one — and what to run on CPU instead — rarely gets written down as a proper decision framework. Guillermo Ruiz and Christian Melendez, both Senior Specialist SAs at AWS, published exactly that as an official EKS best practices guide. The framing is right from the start: CPU and GPU are complementary, not competitive, and as agentic pipelines grow more complex, the CPU surface grows with them — every GPU inference call is surrounded by tool execution, context assembly, vector search, guardrails, and orchestration logic that all run on CPU.
The guide gives you four dimensions to evaluate any workload (model size and precision, latency and throughput SLOs, workload type, cost and capacity constraints), a decision matrix covering everything from SLMs and embeddings to fine-tuning and compliance-sensitive inference, and two production patterns worth reading carefully. The first is an agentic SLM pre-filter: a quantized 1–8B model on CPU handles the majority of agent requests end-to-end, with a routing layer escalating only genuinely complex cases to a GPU-hosted LLM. The second is high-density model farms, where bin-packing hundreds of small models across CPU nodes delivers better economics than dedicated GPU instances for low-QPS endpoints. The benchmark workflow section is the part to bookmark — cost-per-1,000-queries at your target p95 latency is the right metric, and the guide walks you through how to run it before committing to an instance family.
Most EKS multi-tenancy content stops at namespace isolation and IRSA setup — the architecture that works fine at dozens of tenants and starts showing seams around a few hundred. Shawn Zhang, Senior Specialist SA at AWS working on millions-scale GenAI deployments, is three parts into a series documenting what actually breaks at 100,000 tenants: IP space exhaustion, pod density limits, isolation trade-offs, and storage patterns that don’t survive the math at that scale.
Part 3 — the one published this week — is about the limits that interact. The ceiling you hit after upgrading your control plane tier and finding the symptom didn’t move, because the actual constraint was somewhere else entirely. Three IAM patterns for tenant identity are compared; two hit the same quota wall, and only one walks past it — by changing what tenant identity fundamentally means rather than tuning parameters within the same model. Parts 1 and 2 cover networking, pod density, isolation, and storage. If your team is building a multi-tenant agent platform on EKS today and planning for scale, this is the series to read before you commit to an architecture you’ll be refactoring at 10,000 tenants.
⭐Track Inter-AZ and NAT Gateway Traffic with EKS Container Network Observability — Arik Porat, AWS
Inter-AZ data transfer charges on EKS are one of those costs that accumulate silently — every Pod talking to a dependency in a different Availability Zone pays a per-GB charge that doesn’t show up until your bill arrives. Without visibility into which specific services are generating that traffic, you’re making architectural changes blind: you might topology-spread your Pods across AZs for availability and quietly double your data transfer bill in the process. Container Network Observability in EKS gives you near-real-time, pod-level network flow data so you can see exactly which workloads are driving cross-zone and NAT gateway costs before you get the invoice.
The blog walks through four steps: enabling Container Network Observability on your cluster, using traffic distribution control to pin service communication within the same AZ where latency and cost both benefit, replacing NAT gateway egress with VPC endpoints for AWS services that support it, and automating ongoing monitoring with an AI agent for anomaly detection. The inter-AZ topology piece is the one to prioritize first — for most EKS clusters running multi-service AI workloads, cross-zone inference calls and embedding lookups are among the highest-volume traffic patterns, and keeping them zone-local is a straightforward architectural change once you know where to look.
- Announcements 📢
📢Kubernetes v1.36: User Namespaces Finally Reaches GA
One of the foundational security assumptions in early container design was that a process running as root inside a container was not root on the host. In practice, that separation was incomplete — a successful container escape often led directly to host-level root access. User Namespaces fix this at the kernel level: a process that appears to run as UID 0 inside the container is remapped to an unprivileged UID on the host, so even if it escapes the container boundary, it lands without privileges.
This feature has been in development since Kubernetes 1.25 and finally hits GA in 1.36. For EKS teams running multi-tenant workloads — multiple teams’ Pods on shared nodes — enabling User Namespaces is the isolation primitive that makes “different teams, same node” a defensible architecture. It’s also worth reading alongside the Dirty Frag CVEs covered in the Security section this edition: User Namespaces wouldn’t have blocked those specific kernel exploits, but it’s the right layer to harden before the next one.
📢Kubernetes v1.36: In-Place Vertical Scaling for Pod-Level Resources Graduates to Beta
Vertical scaling in Kubernetes has always meant a restart — you update a Pod’s CPU or memory limits, Kubernetes terminates it and creates a new one. For stateless web services that’s acceptable. For a GPU-loaded inference Pod that takes 3–5 minutes to load a model into VRAM and warm up, a restart for a resource adjustment is expensive and disruptive, especially when the change is just accommodating a traffic spike.
In-place vertical scaling lets the kubelet adjust CPU and memory limits on a running Pod without terminating it. The Pod keeps its GPU allocation, its loaded model, its warm cache — and gets more (or fewer) CPU and memory resources applied live. This is Beta in 1.36, which means it’s stable enough to test in staging environments on EKS. Teams doing dynamic inference scaling today with HPA on custom metrics should look at combining this with VPA for a cleaner resource management story.
📢NVIDIA Open-Sources NVCF: GPU Cloud Functions for Multi-Cluster Kubernetes
Running GPU workloads across multiple Kubernetes clusters — routing inference requests to the right region, autoscaling across mixed GPU types, managing function lifecycle and observability from a single control plane — has been possible if you were a DGX Cloud customer. For everyone else it was a DIY problem. NVIDIA quietly pushed NVCF public this week under Apache 2.0, bringing those primitives to anyone running their own GPU infrastructure.
The model is two workload types: Functions for long-running invokable services like inference and streaming, and Tasks for async batch jobs like fine-tuning, evaluation, and data prep. Both ship as containers or Helm charts. Underneath, NVCF handles GPU cluster integration across regions, load-balanced invocation routing, multi-cluster autoscaling, and mixed GPU type pooling. If you’ve been stitching together this layer manually on EKS — separate clusters per GPU type, custom routing logic, per-cluster autoscaling configs — NVCF is worth evaluating as the unified control plane that replaces that glue.
📢AWS Neuron DRA Driver: Kubernetes-Native Trainium Scheduling on EKS
Scheduling workloads onto Trainium instances on EKS has historically required either custom scheduler extensions or manual node selection — infrastructure complexity that sits between ML engineers and the hardware they need. The Neuron DRA driver changes that by plugging Trainium directly into Kubernetes’ Dynamic Resource Allocation framework, the same scheduling layer that now handles GPU prioritized lists and MIG partitioning in 1.36.
The design separates infrastructure and ML concerns cleanly: platform teams define reusable device templates describing the Trainium topology, and ML engineers consume those templates without needing to understand the underlying hardware. Multiple workloads can share nodes without conflicting resource claims. For EKS teams already evaluating Trainium 3 and 4 as an alternative to GPU instances, this is the piece that makes it operationally viable — Kubernetes-native resource management without a parallel scheduling system to maintain alongside it.
📢DRA for Elastic Fabric Adapter: Topology-Aware High-Performance Networking on EKS
Distributed training on EKS has a well-known scheduling problem: you can place GPU Pods on topology-aware nodes, but the high-performance network interfaces connecting those GPUs — EFA adapters — were still allocated without awareness of where the traffic actually needs to flow. A training job landing on the right GPU nodes but with suboptimal EFA assignment still pays the latency cost of non-optimal paths between accelerators.
DRA for EFA brings the same topology-aware allocation model to network interfaces that DRA already brings to GPUs. The scheduler now places EFA adapters to maximize utilization and ensure data flows through the most efficient paths to accelerators — relevant for any tightly coupled distributed training or inference workload where NCCL collective operations are on the critical path. Combined with the Neuron DRA driver and the DRA GPU updates in Kubernetes 1.36, EKS now has a coherent hardware-aware scheduling story across compute and networking together.
📢EKS Provisioned Control Plane: 99.99% SLA and New 8XL Tier
The EKS control plane has historically been a shared responsibility — AWS manages it, but the SLA was 99.95% and the largest scaling tier capped API request throughput at a level that large GPU training clusters could saturate during coordinated scaling events. Two changes land together: the SLA moves to 99.99% for Provisioned Control Plane clusters, and a new 8XL tier doubles the API request processing capacity of the previous largest option. The 8XL tier is specifically positioned for ultra-scale AI/ML training, large-scale data processing, and workloads where control plane responsiveness is a hard operational requirement — the kind of cluster where Karpenter is simultaneously scheduling hundreds of GPU nodes and the API server becomes the bottleneck before the compute does.
Community & Career 🤝
🤝AWS DevOps Agent on EKS: Autonomous Troubleshooting Deep Dive — Arshad Zackeriya
Arshad Zackeriya (AWS Hero, Senior Engineer at Xero) published a new DevOps with Zack episode diving into the AWS DevOps Agent specifically through the lens of EKS incident response — autonomous troubleshooting, interactive ChatOps workflows, and proactive prevention patterns. AWS DevOps Agent went GA earlier this year and the EKS angle is where it gets interesting: the agent can correlate across CloudWatch, cluster events, and application logs to diagnose what a human would spend 30 minutes piecing together manually. Worth watching if you’ve been meaning to evaluate it beyond the launch blog post.
🤝Free Workshop: Platform Engineering on EKS with Argo CD, Kargo, ACK, and Kiro — AWS
AWS is running a free hands-on workshop covering how to build an Internal Developer Platform on EKS end-to-end — self-service provisioning, GitOps deployments with Argo CD, canary rollouts, automated dev-to-prod promotions with Kargo, AI-assisted platform code with Kiro, and DORA metrics to measure it all. The toolchain is the right one: ACK for Kubernetes-native AWS resource management, Kargo for environment promotion, Kiro for the AI-assisted layer. If platform engineering on EKS has been on your learning list but slide decks haven’t moved the needle, this is a direct hands-on path in at no cost.
🤝NemoClaw on kagent: Running Always-On AI Assistants Under Kubernetes Governance — Solo.io
OpenClaw-style always-on agents have a fundamental enterprise problem: when an agent runs on a laptop, it inherits the entire identity of that machine — SSH keys, browser sessions, git credentials, cloud CLI tokens. That’s fine for a single developer. Scale it to thousands of employees and you have thousands of shadow identities inside your org with no unified policy, no audit trail, and no revocation model. NVIDIA’s NemoClaw adds a sandboxed runtime layer around OpenClaw to scope what the agent can do on a single host. But scoping execution and scoping governance are two different problems.
Solo.io’s contribution to kagent closes the second half. NemoClaw handles execution isolation — what the agent can touch on its host. kagent, a CNCF Sandbox project with 300+ contributors from Microsoft, Amazon, Oracle, and others, handles the Kubernetes-level governance layer: identity issuance, policy enforcement, observability, and lifecycle management across a fleet of agents running on shared infrastructure. The division is clean and intentional — NemoClaw scopes the agent’s execution, kagent scopes the agent’s governance. For platform teams already running AI workloads on EKS, this is the pattern that makes always-on assistant agents an operationally viable deployment target rather than a security conversation-stopper.
- Highlights ✨
✨Benchmarking AI Agent Retrieval Strategies on Kubernetes Bug Fixes — Brandon Foley, CNCF Blog
AI agents that help with Kubernetes operations — suggesting fixes, diagnosing issues, generating runbooks — need to retrieve the right context before they can give useful answers. The retrieval strategy you pick (keyword-based BM25, dense vector embeddings, a hybrid of both, or a more agentic search loop) directly affects how accurate those answers are. Brandon Foley’s piece on the CNCF blog runs an empirical comparison of all four on a very specific, practical task: generating correct fixes for real Kubernetes bugs from issue descriptions. Useful both as a benchmark to reference and as a sanity check before your team commits to a retrieval stack for any K8s-aware AI agent in production.
✨Kubernetes AI Gateway Working Group Announced
The Kubernetes community has formed a dedicated AI Gateway Working Group to extend Gateway API with inference-specific primitives: model routing, token-based rate limiting, and semantic caching. These are traffic patterns that don’t map cleanly onto HTTP routing semantics — a request to an LLM isn’t a fixed payload, it’s a variable-length token stream with cost that scales non-linearly. Early days, but this is the working group that will define how Kubernetes handles AI inference traffic at the routing layer for the next several years. Worth watching if your team is building or evaluating an inference gateway on EKS.
Most MCP servers today run on localhost. Moving them to production surfaces the same problems any internal microservice faces — and a few new ones specific to the protocol. The reference implementation here is on ECS, but the patterns transfer directly to EKS: Streamable HTTP is stateless by default and scales horizontally, but multi-step stateful workflows need Mcp-Session-Id headers and sticky routing at the load balancer layer; MCP servers belong in private subnets with only the client-facing layer internet-reachable; and inter-service calls from agent to MCP server to data store should route through a service mesh rather than application-level retry logic. The protocol is new. The infrastructure patterns are not.
✨Agent Sandbox: A Kubernetes-Native Runtime for Long-Running AI Agents (SIG Apps)
Deployments assume stateless, replaceable Pods. StatefulSets assume ordered, stable storage. Neither fits the actual runtime shape of an AI coding agent or a persistent development environment — a singleton workload that needs stable identity, optional persistent storage, and the ability to write code and execute commands across multiple turns without being rescheduled. Agent Sandbox is a SIG Apps project introducing a declarative CRD-based API for exactly this shape. Each sandbox gets a stable identity and a lightweight single-container VM-like experience built on Kubernetes primitives. Alpha, but the right primitive — if your team is running AI agents on EKS today and duct-taping StatefulSets to do it, this is the upstream direction to watch.
✨AWS Agent Toolkit GA: Official MCP Server + Skills for Building on AWS
If you use Claude Code, Kiro, or Codex to work with AWS infrastructure, three problems come up repeatedly: stale training data missing newer services, agents defaulting to CLI instead of CDK, and IAM policies wider than they need to be. The AWS Agent Toolkit is AWS’s direct answer — a managed MCP server with authenticated access to all AWS APIs, real-time documentation search, and on-demand skills covering containers, CDK, serverless, observability, and more. The governance piece is the part that matters for production use: IAM context keys let you write policies that differentiate what agents can do from what humans can do, and every call goes through CloudTrail. A single /plugin install aws-core@agent-toolkit-for-aws in Claude Code gets you there.
Cross-region DR for EKS is one of those requirements that teams acknowledge as important and defer until something forces the conversation. The gap isn’t understanding the concept — it’s having a tested, end-to-end implementation that covers both application configuration and persistent data, not just one or the other. This blog walks through a complete implementation using AWS Backup: deploy a stateful application in a source region, back up cluster state and persistent volumes, copy the backup cross-region, and restore the full application with stateful data intact into a pre-provisioned secondary cluster. Worth bookmarking as the reference implementation before you need it rather than building it under pressure.
✨IREN Acquires Mirantis for $625M — What It Means for Platform Teams
IREN, a power-and-data-center company pivoting from Bitcoin mining to AI cloud, is buying Mirantis for the Kubernetes and orchestration stack it needs to be a credible cloud provider rather than just a colocation. The deal makes strategic sense for IREN. The question for platform teams is what happens to the open-source projects Mirantis stewards — k0s, k0smotron, and Lens — when the new owner’s customer profile shifts toward AI-cloud delivery. The two quarters after close are when contribution priorities and roadmaps actually reflect the new ownership. If your platform depends on any of these: k0smotron for hosted control planes maps cleanly to vCluster, k0s for lightweight or edge K8s has k3s and Talos as credible alternatives, and Lens in the desktop lane has Headlamp and the newly-released Skyhook Radar. Pre-evaluate now while the decision is yours to make on your timeline.
🎉 Sponsor Section
At the moment, we don’t have a sponsor for this edition, but we look forward to working with companies and organizations that support the EKS & AI Infrastructure community in future editions. If you or your company is interested in sponsoring, please contact us at 📧 thecloudtechforall@gmail.com
📝 Words from the Author
I’ve been thinking about the people who showed up before there was anything to show up for.
Every community has that origin story, if you look closely enough. The first meetup where you booked a room for fifty people and twelve showed up. The first newsletter edition you hit publish on and then refreshed your inbox for three hours waiting for someone — anyone — to say they read it. The first talk where you looked out from the stage and counted the audience on one hand and gave it everything anyway. No recording. No LinkedIn post blowing up afterward. Just the room, the people in it, and the thing you had to say.
Those moments don’t make the highlight reel. Nobody posts about the meetup that almost didn’t happen. But they’re the ones that actually built the thing — because they prove to you, before anyone else believes it, that you’ll keep going when the conditions aren’t favorable. And in community building, the conditions are almost never favorable in the beginning.
What I’ve noticed is that the people who stick around long enough to see something grow rarely credit themselves for it. They credit the community. They credit the speakers, the sponsors, the attendees. Which is true — communities are built by the people in them, not just the people who started them. But someone had to be unreasonably optimistic first. Someone had to send the invite before they knew if anyone would accept it.
If you’re somewhere in that early stretch right now — the phase where you’re building in public and it feels mostly quiet — keep going. The people who show up when there’s nothing yet are the ones who make the something possible. And one day you’ll look back at this exact period and realize it was the most important part.
Happy Building. 😎



